试题详情
- 简答题下表中列出了4个点的两个最近邻。使用SNN相似度定义,计算每对点之间的SNN相似度。
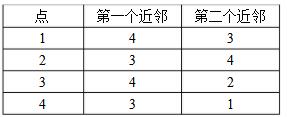
- SNN即共享最近邻个数为其相似度。
点1和点2的SNN相似度:0(没有共享最近邻)
点1和点3的SNN相似度:1(共享点4这个最近邻)
点1和点4的SNN相似度:1(共享点3这个最近邻)
点2和点3的SNN相似度:1(共享点4这个最近邻)
点2和点4的SNN相似度:1(共享点3这个最近邻)
点3和点4的SNN相似度:0(没有共享最近邻) 关注下方微信公众号,在线模考后查看

热门试题
- OLAP系统和OLTP系统的主要区别包括
- 数据挖掘的主要任务是从数据中发现潜在的规
- 存放最低层汇总的方体称为()。
- 当前的数据挖掘研究中,最主要的三个研究方
- 简述数据仓库ETL软件的主要功能和对产生
- 关联规则
- 聚类分析可以看作是一种非监督的分类。
- DBSCAN是相对抗噪声的,并且能够处理
- 通过聚集多个分类器的预测来提高分类准确率
- 以下哪种方法不属于特征选择的标准方法:(
- 在基本K均值算法里,当邻近度函数采用()
- 层次聚类方法包括哪些?
- 定义下列数据挖掘功能: 关联、分类、聚类
- 列举离群点挖掘的常见应用。
- 大型数据库中的关联规则挖掘包含两个过程(
- 寻找数据集中的关系是为了寻找精确、方便并
- 列举操作型数据与分析型数据的主要区别。
- 下面关于数据粒度的描述不正确的是()
- 进行数据规范化的目的是()。
- 数据概化是指:()